Using LLMs to explore Pune’s History

Large Language Models (LLMs) have basically soaked up a ton of information from all the text they’ve been fed. It’s pretty mind-blowing to see how much these AI systems know about our world.
Recently, I tried out an experiment to check out how AI views the history of Pune, a city in India with a really long and rich past. Pune’s history spans centuries, and it still proudly showcases its deep-rooted heritage. Different rulers have left their mark on the city over the years, and if you look at the city’s layout, you can actually see how it’s connected to different historical periods and how it’s grown over time.
I looked at the database of heritage places in Pune generously provided by Government of India and Pune Municipal Corporation through the OpenData, a Digital India initiative. Places mentioned in this dataset spans wide range of history from 9th Century to 20th century.
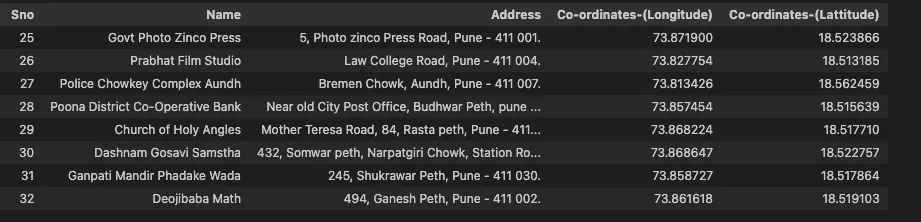
We decided to take a closer look at each of the sites and tried to find their corresponding Wikipedia pages based on the information provided in the Name column of our dataset. We managed to succeed in 77% of our attempts during this phase, identifying 146 heritage places with Wikipedia pages.
With that key information in hand, next move was to extract content from these Wikipedia pages and feed it into our LLM AI model. We achieved this using Python and Wikipedia APIs, seamlessly integrating the wealth of knowledge from these pages into our analysis.
import wikipedia
def get_wiki_summay(x):
summary = ""
try:
summary = wikipedia.summary(x.split("/wiki/")[1])
except Exception as e:
pass
return summary
heritige_urls_df["wiki_summary"] = heritige_urls_df["article_url"].apply(
get_wiki_summay
)After obtaining the text, we generated embeddings, which essentially translate the text query into vector representations. AI models, particularly LLMs, boast dense representations for text, encapsulating knowledge in numerical form. In this experiment, we employed two distinct models. The first one leveraged a BERT-based sentence encoder from HuggingFace, yielding a vector of 384 dimensions. The second model utilized OpenAI embeddings through LangChain, yielding embedding vectors with a size of 1586, making them four times as expansive as the sentence encoder’s output.
import pandas as pd
## first model
from sentence_transformers import SentenceTransformer
## second model
from langchain.embeddings import OpenAIEmbeddings
def compile_text(x):
text = f"""Name: {x['Name']},
Address: {x['Address']},
wiki_summary: {x['wiki_summary']}
"""
return text
sentences = df.apply(lambda x: compile_text(x), axis=1).tolist()
# Sentence Tranformer model
model = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")
output = model.encode(
sentences=sentences, show_progress_bar=True, normalize_embeddings=True
)
# OpenAI model
embeddings = OpenAIEmbeddings(openai_api_key="your api key")
output = [embeddings.embed_query(x) for x in (sentences)]
df_embedding = pd.DataFrame(output)After obtaining the vectors for each place, we proceeded to classify the data into distinct groups using unsupervised clustering algorithms, with KMeans being our weapon of choice. However, considering the relatively small sample size of just 146 heritage places in this task, we first applied PCA transformation to condense the dimensions. Remarkably, with approximately 30 dimensions for the sentence model and 50 dimensions for the OpenAI model, we managed to capture 70% of the variance, which appeared quite satisfactory for our objectives.
When it came to determining the cluster size, we faced the classic conundrum of choosing a suitable clustering quality metric. Beyond just achieving the best grouping, we also valued factors like ease of interpretation and performance across both models. Ultimately, we converged on three as the optimal cluster size using the elbow method for the sentence encoder model, while the same size seemed “good enough” for the OpenAI model.
Now, let’s delve into the exciting part: how AI goes about grouping these fascinating places within the city!
Below are the clusters formed by sentence encoder model

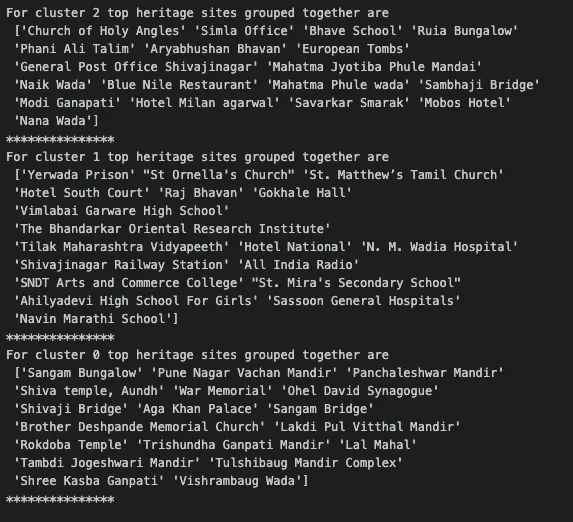
In our analysis, we distinctly identified three clusters that delineate Pune’s historical evolution. The first cluster represents Pune before 1850, a time marked with influence of temples, wadas. The second cluster signifies Pune’s transformation under British rule after 1850, and the third encapsulates modern Pune, characterized by its proliferation of educational and government institutions.
Cluster two, while rich in ancient temples, also intertwines with the royal heritage of Pune, often invoking associations with terms like “Raj.” Raj Bhavan is thus linked with city’s historical roots. A particularly intriguing heritage site within this cluster is the “Brother Deshpande Memorial Church,” named in honor of Ramchandra Pralhad Deshpande. Interestingly, unlike other church locations such as “St. Ornella’s Church” or “St. Matthew’s Tamil Church,” it did not fall into cluster 1. The reason becomes apparent when considering the church’s location in Kasba Peth, one of the city’s oldest districts and name which sounds Indian. It seems our model was astutely capturing this historical nuance.
Below, we have the clusters visually represented on a map. In the center, we observe the historical heart of Pune (cluster 2) depicted in orange, with the European influence extending to the eastern side highlighted in blue. On the other hand, the more contemporary heritage sites, such as educational institutions around the Deccan, Law college Road , are marked in green. Here you can see the map in detail.
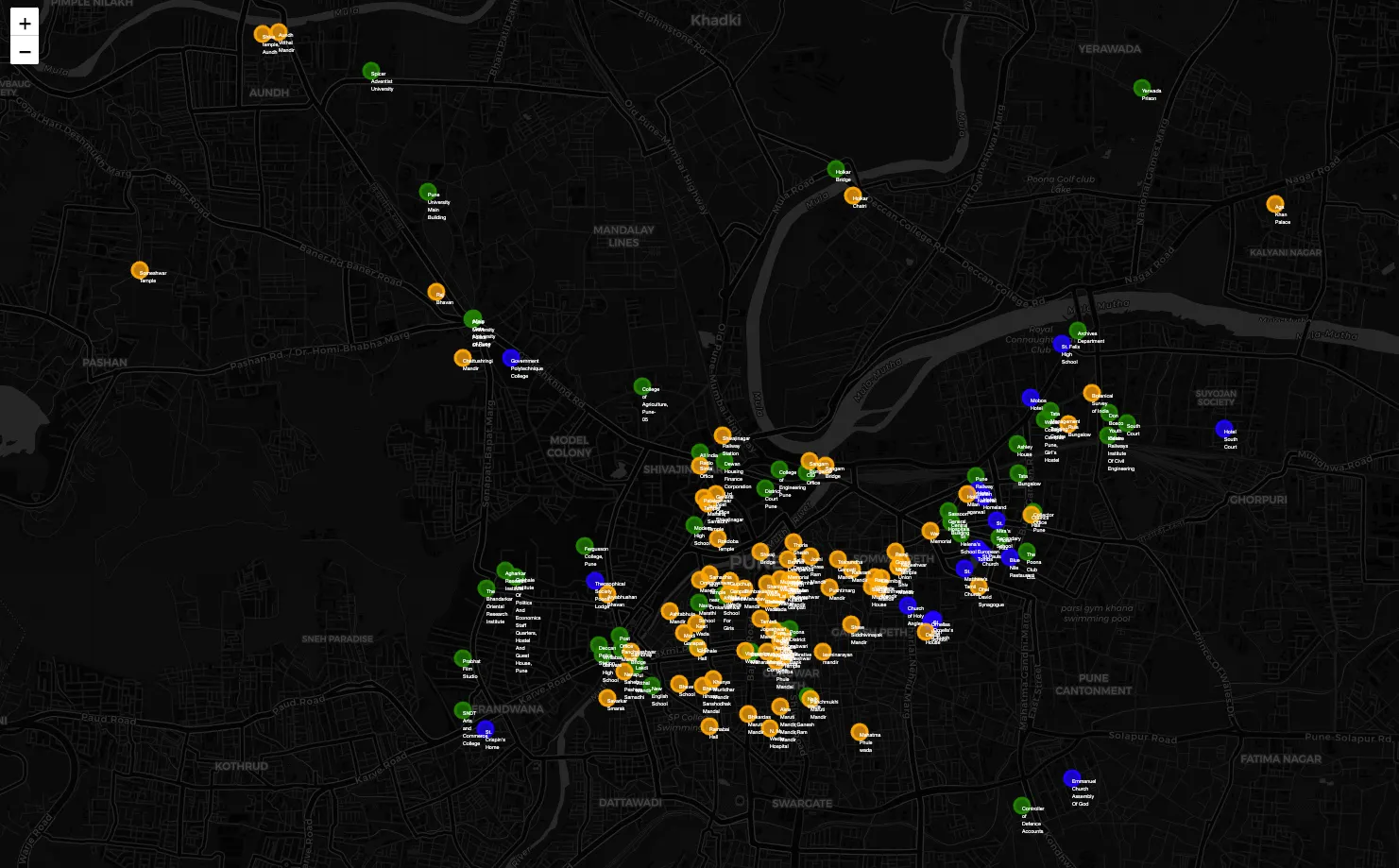
One intriguing aspect of the model lies in its capacity to categorize two closely situated locations into distinct clusters, despite their strikingly similar addresses. While the address information was included in the input text, the model’s embeddings effectively differentiated between them based on their respective Wikipedia content. For instance, “Chattushringi Mandir” and “Government Polytechnique College,” both located on opposite sides of the same road, were grouped into separate clusters. Here, you can find the results obtained using the OpenAI model.
View both the model clusters here. Feel free to connect if you want to discuss more.
References:
- https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2
- https://towardsdatascience.com/mastering-customer-segmentation-with-llm-3d9008235f41 (Huge thanks for inspiration!!)
- https://gist.github.com/scionoftech/0f35d5e231be2cf46823d774023268b6
- http://opendata.punecorporation.org/Citizen/CitizenDatasets/Index?categoryId=3
- Photo by Prasad Bhalerao on Unsplash
